Appearance
因子检验
FactorAnalysisEngine
FactorAnalysisEngine 是因子检验的 “容器”,通过 append 方法添加数据处理器(如极值处理、标准化)和分析器(如 IC 分析、分组收益分析),形成标准化的检验流程,支持一键执行多维度检验。
特点:
- 不限因子的资产类型和数据频率,因子检验的使用范围更广;
- 支持传入自定义收益率,不再局限于股票日终收益率;
- 支持传入自定义资产行业,更灵活地计算 IC 行业分布;
- 对于多日调仓的场景,使用滚动调仓计算 IC 和因子收益,从而减少路径依赖;
- 通过构造管道进行数据处理和分析计算,方便用户反复地进行检验和分析;
- 可单独计算 IC 分析/分组分析/因子收益率,自定义输出结果更有针对性;
- 支持输出数据处理后的因子值,处理结果更加透明。
注:目前仅支持传入因子值,不支持传入因子定义,如Factor('close')需使用execute_factor计算后再传入。
1. 预处理可选项
极值处理
python
Winzorization(method='mad')定义因子极值处理逻辑,支持使用 3 绝对值差中位数法、3 标准差法、2.5% 百分位法等方式处理因子值。
参数
| 参数名 | 说明 |
|---|---|
| method | 可选择 mad:3 绝对值差中位数法; std:3 标准差法; percentile:2.5%百分位法 |
标准化
python
Normalization()定义因子标准化处理逻辑,用于对输入的因子值进行标准化处理。
因子中性化
python
Neutralization(industry='citics_2019', style_factors='all')定义因子中性化处理逻辑,支持按中信 2019 行业、申万行业以及 size、beta、momentum 等风格因子进行中性化。
参数
| 参数名 | 说明 |
|---|---|
| industry | 行业中性化使用的行业分类,目前仅支持股票。可选citics_2019或者sws,None代表不做行业中性 |
| style_factors | 需要进行中性化的风格,底层数据为米筐风险因子,目前仅支持股票。None代表不做风格中性;all代表所有风格;支持通过 list 传入单个或者多个风格,可选size市值,beta贝塔,momentum动量,earnings_yield盈利率,growth成长性,liquidity流动性,leverage杠杆率,book_to_price账面市值比,residual_volatility残余波动率,non_linear_size非线性市值 |
2. 因子分析器可选项
IC 分析
python
ICAnalysis(rank_ic=True,industry_classification=None, max_decay=None)定义 IC 分析逻辑,支持计算排序 IC 或普通 IC,也支持按申万行业、中信 2019 行业或自定义分组计算 IC 行业分布与 IC 衰减。
参数
| 参数名 | 说明 |
|---|---|
| rank_ic | 是否使用因子值的排名计算 ic。为 False 时,使用因子值计算 ic |
| industry_classification | 分组依据,None代表不计算 IC 行业分布;可输入sws或citics_2019,仅支持股票因子;对于股票之外的资产类型,可传入自定义分组pd.Series or dict,其中index或key为资产 id |
| max_decay | 计算ic_decay时使用的最大滞后期数,若传入None,则不计算 IC 衰减 |
分组收益分析
python
QuantileReturnAnalysis(quantile=5, benchmark=None)定义分组收益分析逻辑,支持按分组数量对因子值分组,并结合基准指数分析各组收益数据。
参数
| 参数名 | 说明 |
|---|---|
| quantile | 分组数量 |
| benchmark | 基准,默认为None,支持传入指数代码 |
因子收益率计算
python
FactorReturnAnalysis()定义因子收益率计算逻辑,用于计算因子收益率相关数据。
3. 构建管道
需先实例化引擎,再通过 engine.append(('name', processor) 逐步添加组件。
python
engine = FactorAnalysisEngine()引擎通过append方法接受一个tuple,格式为(name, processor),name不能重复。如需添加多个处理器或分析器,请逐步添加,例如:
python
# 数据处理
engine.append(('winzorization-mad', Winzorization(method='mad')))
engine.append(('normalization', Normalization()))
# IC分析
engine.append(('rank_ic_analysis', ICAnalysis(rank_ic=True)))4. 执行计算
通过analysis传入因子值等数据,执行管道中所有组件的逻辑,返回各分析器的检验结果。
python
engine.analysis(factor_data, returns, ascending=False, periods=1, keep_preprocess_result=False)执行因子检验管道计算,支持传入因子值和收益率数据,并按排序方向、调仓周期和是否保留预处理结果输出各分析器对应的检验结果数据。
参数
| 参数名 | 说明 |
|---|---|
| factor_data | 因子值,类型为pd.DataFrame,index 为datetime,columns 为 order_book_id |
| returns | 收益率数据,可输入daily或pd.DataFrame。如选daily,则函数自动根据get_price_change_rate查询对应 id 的日涨跌幅数据(仅支持股票和指数);如上传pd.DataFrame,其index和columns应和factor_data的相同。(引擎将使用 T 期因子值和 T+1 期收益率进行计算,如果希望使用 T+N 期收益率,用户可自行 shift 收益率数据) |
| ascending | 因子值排序方向,True表示从小到大排序;False则从大到小排序 |
| periods | 调仓周期,即累计收益率的周期。 int 或者list,例如[1,5,10],最多三个周期 |
| keep_preprocess_result | 是否保存预处理数据结果,True表示保存 |
返回
engine.analysis() 返回一个字典,key 为每个分析器的名字,value 为对应组件的结果对象(如 ICAnalysisResult),具体接口和字段见下文。
ICAnalysis 结果
返回ICAnalysisResult 类型的对象,包含以下字段:
| 字段名 | 说明 |
|---|---|
| ic | 各期 IC 值 |
| rolling(window=12) | 计算 IC 滚动均值,可通过window指定窗口数量,最多 20 期 |
| summary() | 计算 IC 统计指标,返回dict类型,计算结果包含以下字段:
|
| ic_decay | ic_decay 序列 |
| ic_industry_distribute | IC 行业分布 |
| show() | 绘制分析结果 |
QuantileReturnAnalysis 结果
返回 QuantileReturnAnalysisResult 类型的对象,包含以下字段:
| 字段名 | 说明 |
|---|---|
| quantile_returns | 各期分组累计收益率序列 |
| quantile_turnover | 各期分组换手率 |
| top_minus_bottom_return | 做多第一组做空最后一组的收益率序列 |
| quantile_detail | 各期分组情况 |
| benchmark_return | 各期基准收益率序列 |
| show() | 绘制分析结果 |
FactorReturnAnalysis 结果
返回 FactorReturnAnalysisResult 类型的对象,包含以下字段:
| 字段名 | 说明 |
|---|---|
| factor_returns | 因子累计收益率 |
| max_drawdown() | 最大回撤值 |
| std() | 因子收益率波动率 |
| show() | 绘制分析结果 |
数据处理结果
当keep_preprocess_result为True时,将按照因子预处理的顺序和名称依次返回因子结果,例如因子管道构建代码为:
python
engine.append(('winzorization-mad', Winzorization(method='mad')))
engine.append(('normalization', Normalization()))返回dict的key中会包含winzorization-mad和normalization。
使用示例
- 基于沪深 300 股票池,计算 20210101 - 20211101 的 pe 因子
python
import pandas as pd
import datetime
from rqfactor import *
import rqdatac
rqdatac.init()
d1 = '20210101'
d2 = '20211101'
f = Factor('pe_ratio_ttm')
ids = rqdatac.index_components('000300.XSHG',d1)
df = execute_factor(f,ids,d1,d2)- 将每日 14:00 的分钟 close 数据合成为新的收益率数据
python
price = rqdatac.get_price(ids,d1,d2,frequency='1m',fields='close',expect_df=False)
target = datetime.time(14, 0)
mask = price.index.get_level_values('datetime').time == target
returns = price[mask].pct_change()
returns.index = pd.DatetimeIndex(returns.index.date)- 构建管道,并将因子值和收益率传入分析器中进行计算
python
engine = FactorAnalysisEngine()
engine.append(('winzorization-mad', Winzorization(method='mad')))
engine.append(('rank_ic_analysis', ICAnalysis(rank_ic=True, industry_classification='sws')))
result = engine.analysis(df, returns, ascending=True, periods=1, keep_preprocess_result=True)
result['rank_ic_analysis'].summary()
# Out:
# P_1
# mean 0.007487
# std 0.243561
# positive 100.000000
# negative 99.000000
# significance 0.628141
# sig_positive 0.301508
# sig_negative 0.316583
# t_stat 0.433625
# p_value 0.665033
# skew 0.067769
# kurtosis -0.774880
# ir 0.030739- 绘制 IC 结果图
python
result['rank_ic_analysis'].show()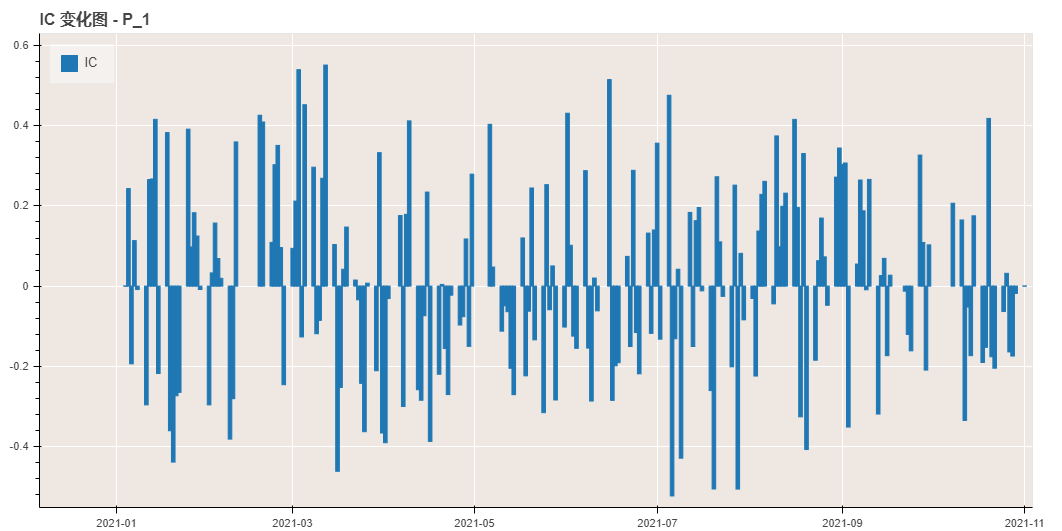
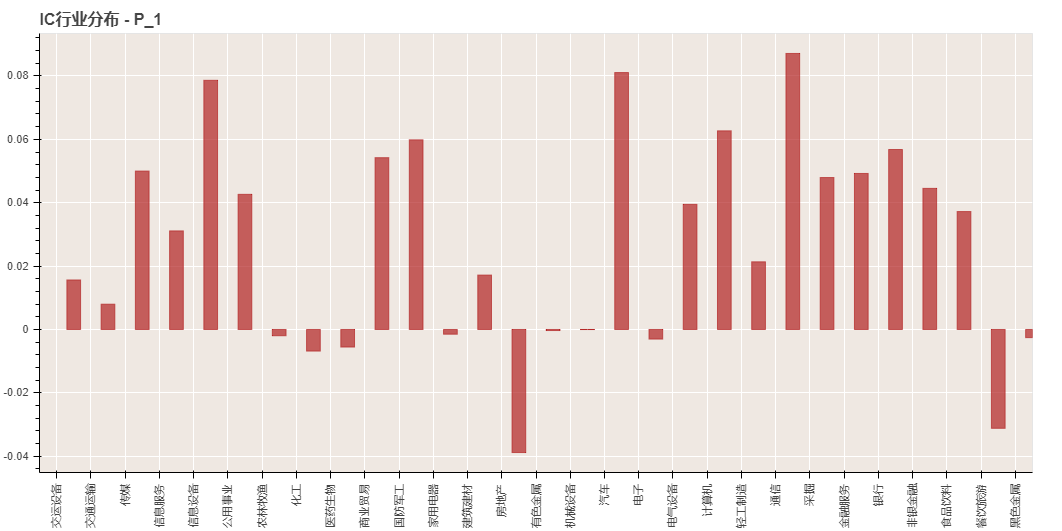
更多示例可参考这里